mysql篇
1.登陆mysql
在phpstudy启用mysql服务,在对应位置终端输入
mysql -u 用户名 -p(密码登陆)
2.常规查询
查询数据库列表
show databases;
-- 一定要注意分号
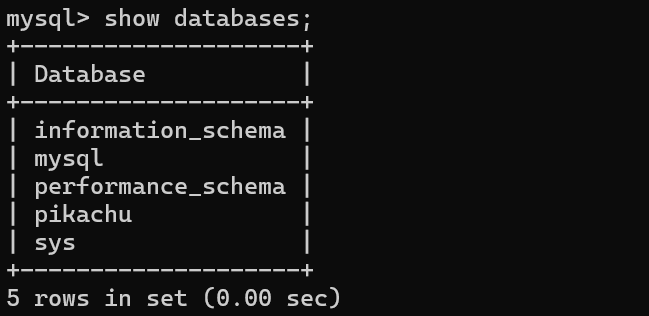
可以看到mysql自带了几个数据库,其中information_schema存储了mysql服务器的所有数据库的信息,mysql数据库存储了用户权限等信息,performance_schema存储了mysql性能相关的信息,sys数据库是mysql5.7新加的一个系统数据库,主要用于简化performance_schema的使用
查询当前使用的数据库
select database();
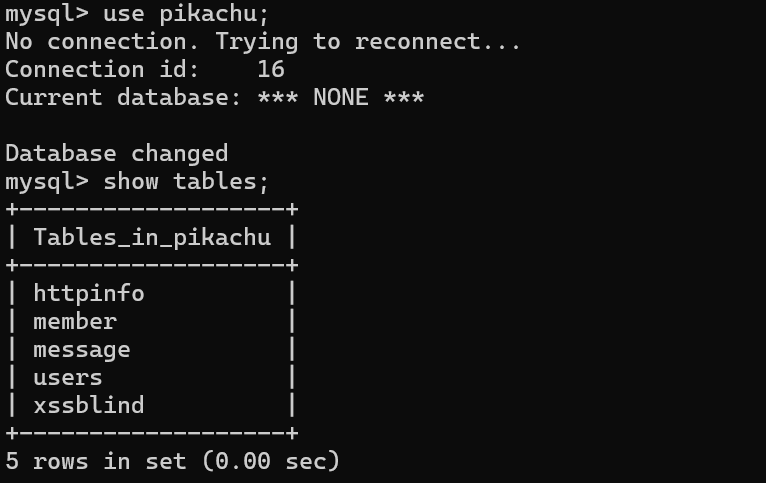
使用数据库
use 数据库名;
查询当前数据库的所有数据表
show tables;
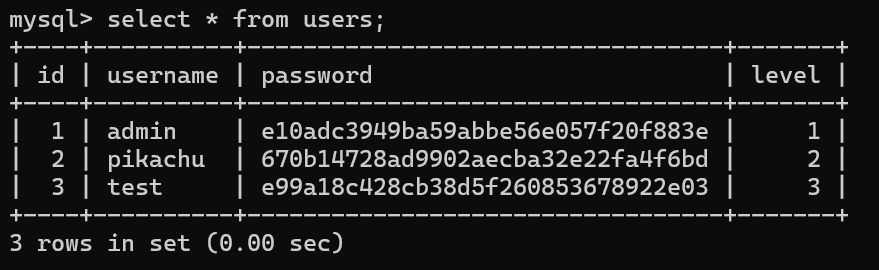
查询数据表结构
select * from 表名;
查询列
select 列名1,列名2 from 表名;
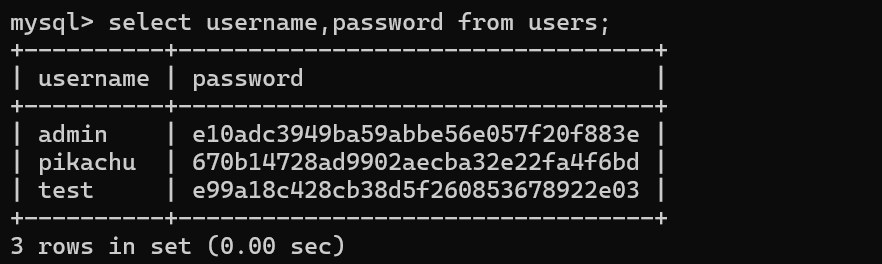
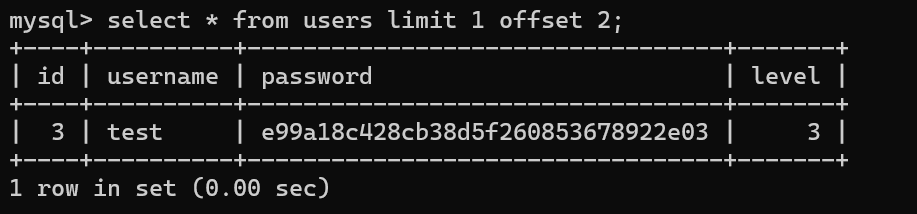
查询行
select * from 表名 limit 数量;
select * from 表名 limit 起始位置,数量; -- 起始位置可以选择0开始
select * from 表名 limit 起始位置 offset 偏移量; -- offset表示从起始位置偏移多少行开始查询
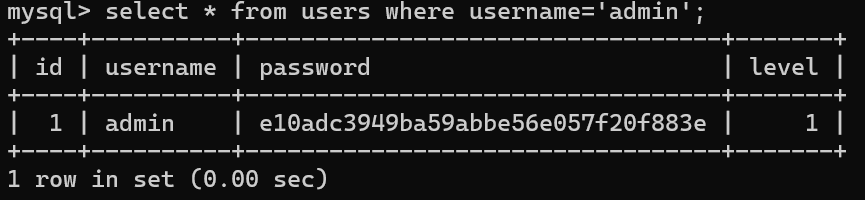
同样可以使用条件查询行
select * from 表名 where 条件;
3.关于information_schema
information_schema本身就是一个数据库,每次创建新内容,都会在information_schema中生成对应的信息表来存储这些信息
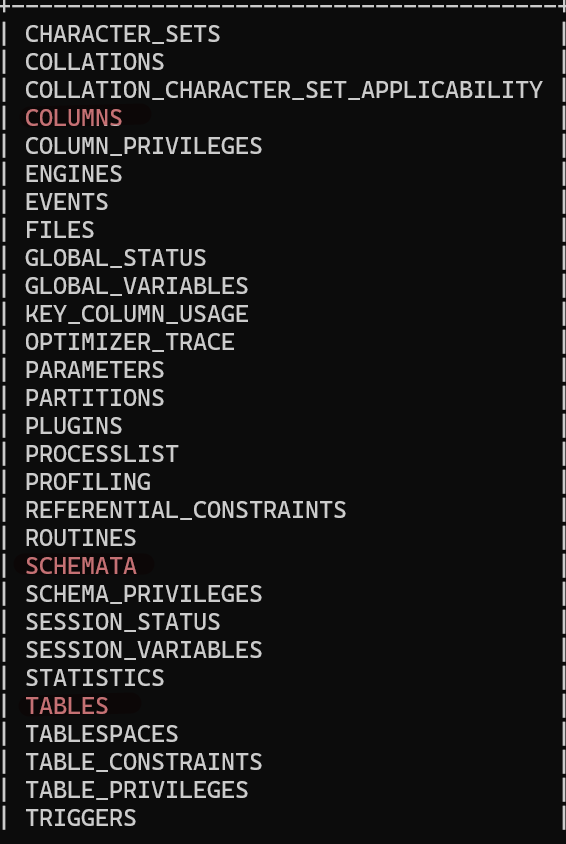
columns:列信息;schemata:数据库信息;tables:表信息;
我们查一下就可以知道除了显示信息,information_schema还显示创建信息时的一些细节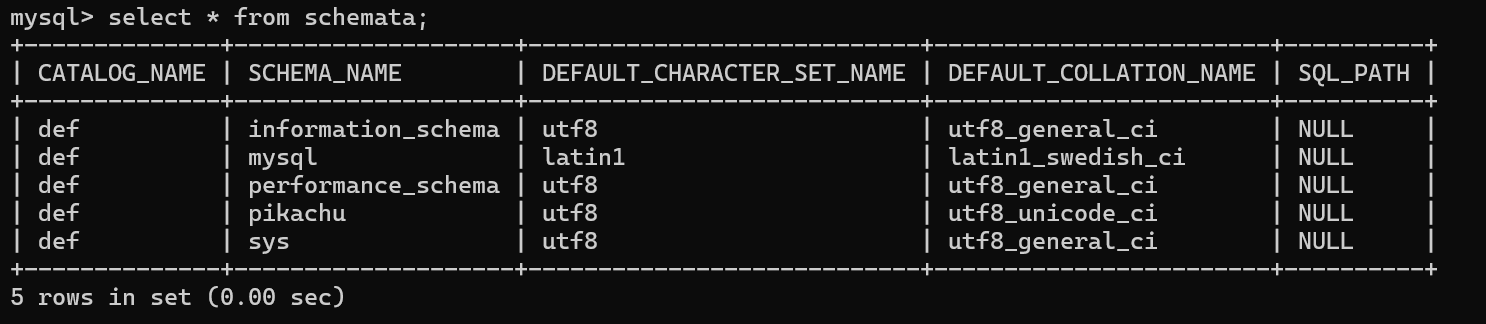
其中,COLUMNS表存储了所有数据库的列信息,该信息表包含column_name,table_name,table_schema三列,分别表示全部列名信息,全部表名信息和全部数据库名信息
这就解释了sql注入查询列名的常用payload
select group_concat(column_name) from information_schema.columns where table_schema=database();
-- database()表示当前使用的数据库
-- group_concat()函数表示将查询结果按逗号连接成字符串返回,而不是表格
再往下看,有CHARACTER_SET_NAME和COLLATION_NAME两列,表示信息使用的编码和字符集
mysql有个特性,就是在使用联合查询时,如果两个查询内容的字符集不一致,则会报错
Illegal mix of collations for operation 'UNION'
我们可以用binary()强制转换字符集
select 1,group_concat(binary(column_name)) from information_schema.columns where table_schema=database();
4.增删改
先创建一个数据库
CREATE DATABASE 数据库名;
创建数据表
CREATE TABLE 表名(
列名1 数据类型(长度) 属性,
列名2 数据类型(长度) CHARACTER SET 字符集 属性,
...
PRIMARY KEY (列名) -- 设置主键,方便识别此表
);
数据类型:
- INT: 整数
- VARCHAR(上限): 可变长度字符串,存多少占多少直到上限
- TEXT: 长文本
- TINYINT: 小整数,常存放0和1
- DECIMAL(m, d): 小数类型,m表示总位数,d表示小数位数
属性:
- NOT NULL: 不能为空
- AUTO_INCREMENT: 自动增长,常用于id主键
- UNIQUE: 唯一,不允许重复
- COMMENT '': 注释

如果设置有误,可以使用ALTER TABLE语句修改表结构
ALTER TABLE 表名 MODIFY 目标列名 数据类型(长度) 属性;
如果想查看注释,被记录在系统表里了
SELECT column_name, column_comment FROM information_schema.columns WHERE table_name = '表名';
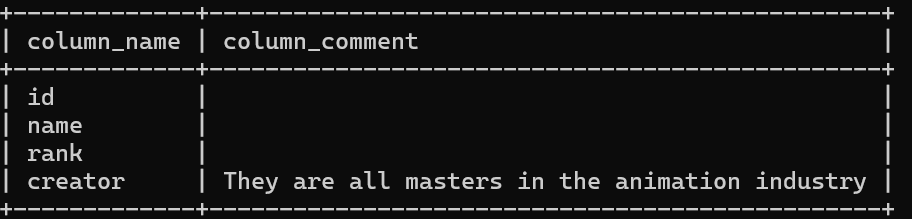 插入数据到表
插入数据到表
INSERT INTO 表名 (列名1, 列名2) VALUES
('对应列名1的数据', '对应列名2的数据'),
('对应列名1的数据', '对应列名2的数据'),
('对应列名1的数据', '对应列名2的数据');

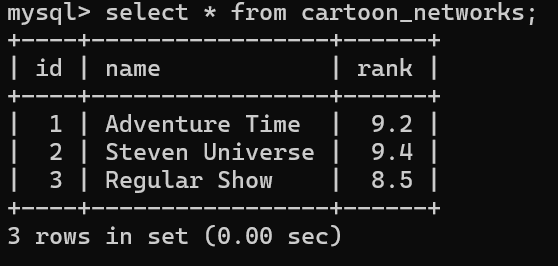
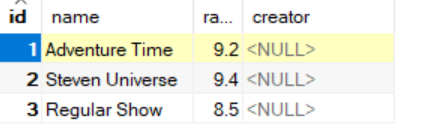
成果
如果想增加新列,可以使用ALTER TABLE语句
ALTER TABLE 表名 ADD 列名 数据类型(长度) 属性 AFTER 目标列名;
-- AFTER表示在目标列名后添加新列
也可以用update语句修改已有数据
UPDATE 表名 SET 列名 = '新数据' WHERE 条件;
比如把所有评分低于9.0的动画片名字后面都加上 (Unpopular)
UPDATE cartoon_networks SET name = CONCAT(name, ' (Unpopular)') WHERE `rank` < 9.0;
删除列表库用DROP,删除数据用DELETE FROM
DELETE FROM cartoon_networks WHERE 列名 = 对应数据;
ALTER TABLE 表名 DROP COLUMN;
DROP TABLE 表名;
DROP DATABASE 数据库名;
5.逻辑判断
逻辑判断多用于WHERE条件查询
范围判断:
WHERE id IN (1, 3, 5) -- 在指定范围内
WHERE id NOT IN (1, 3, 5) -- 不在指定范围内
WHERE id BETWEEN 1 AND 5 -- 在两个值之间,包括边界值
WHERE id NOT BETWEEN 1 AND 5 -- 不在两个值之间,包括边界值
条件判断:
WHERE 条件1 AND 条件2 -- 同时满足两个条件
WHERE 条件1 OR 条件2 -- 满足任一条件
IF(条件, true返回结果, false返回结果) -- 条件判断函数
CASE
WHEN 条件1 THEN 结果1
WHEN 条件2 THEN 结果2
ELSE 结果3
END
-- 多条件判断函数
条件判断语句多用于时间盲注,比如
SELECT * FROM users WHERE id = 1 AND IF(substr(database(),1,1)='s', sleep(5), 1);
6.函数补充
COUNT()聚合函数
COUNT(*)一般用来统计符合条件的行数
而COUNT(列名)用来统计某一列中非NULL值的行数量
SELECT COUNT(*) FROM 表名 WHERE 条件;
SELECT COUNT(列名) FROM 表名;
-- 结果会返回一个数
COUNT(*)也常用于数据分组,我在报错注入的博客里讲过
mysql也自带一些编码函数,说说ctf常用的
ascii字符的转换:
ASCII('A')/ORD('A') -- 返回65
CHAR(65); -- 返回'A'
十六进制转换:
HEX('A') -- 返回41
UNHEX('41') -- 返回'A'
-- mysql不存在url编码函数
进制转换也可以用一个函数解决
CONV(str, from_base, to_base) --返回进制转换后的字符串
7. 句柄
句柄是mysql专有的扩展,用于与数据库储存建立连接直接拿取数据,可以避免使用select语句
但句柄有一个限制那就是作用域只能在一个连接周期内有效,而PHP环境中的连接是瞬时的,也就是说每次请求都会重新建立连接。这意味着我们需要进行堆叠注入
HANDLER 表名 OPEN; -- 打开句柄
HANDLER 表名 READ FIRST WHERE 条件; -- 读取第一行数据
HANDLER 表名 READ NEXT; -- 读取下一行数据
HANDLER users CLOSE; -- 关闭句柄
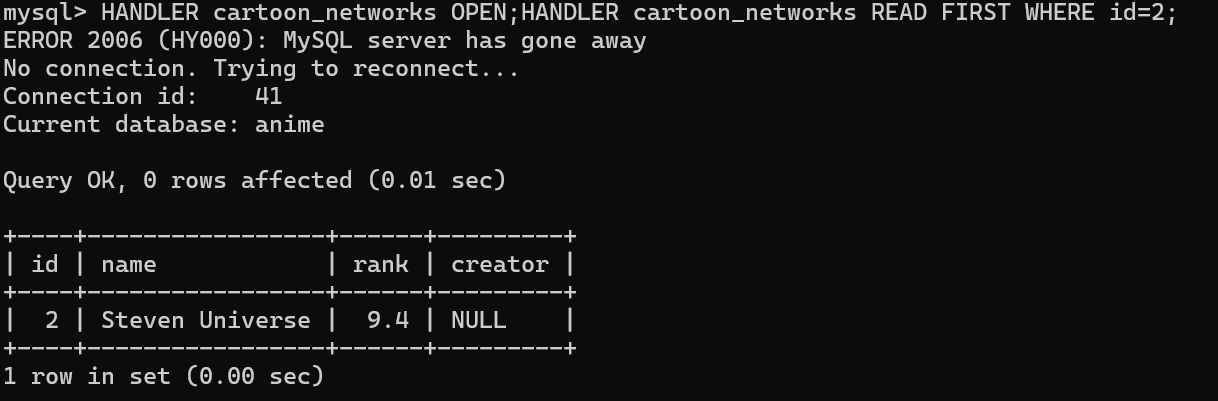
如果是管理数据库,可以直接使用图形化工具。比如phpstudy集成的SQL_Front